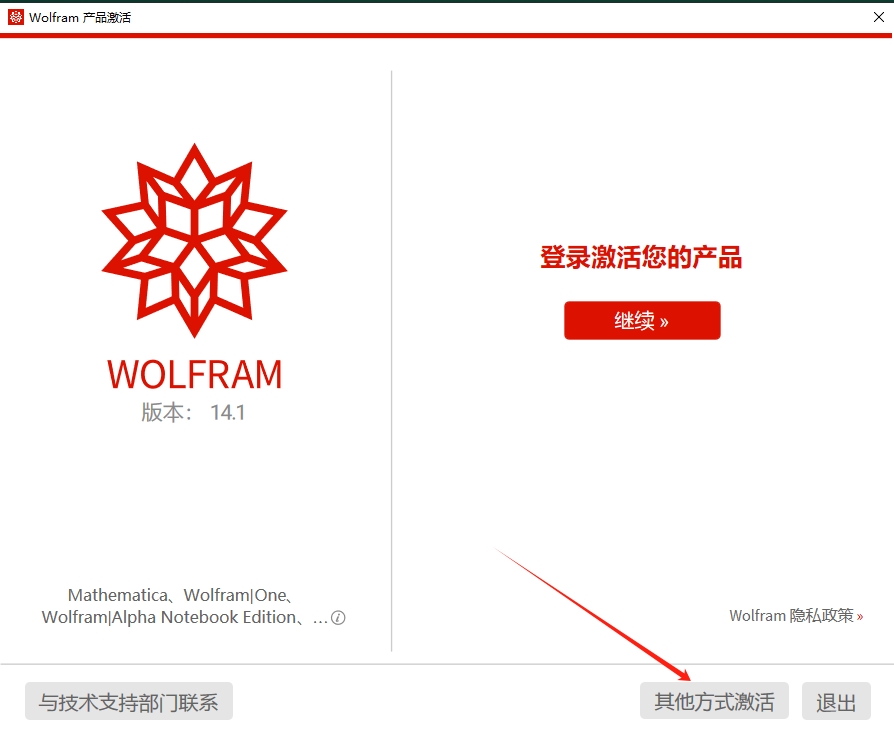
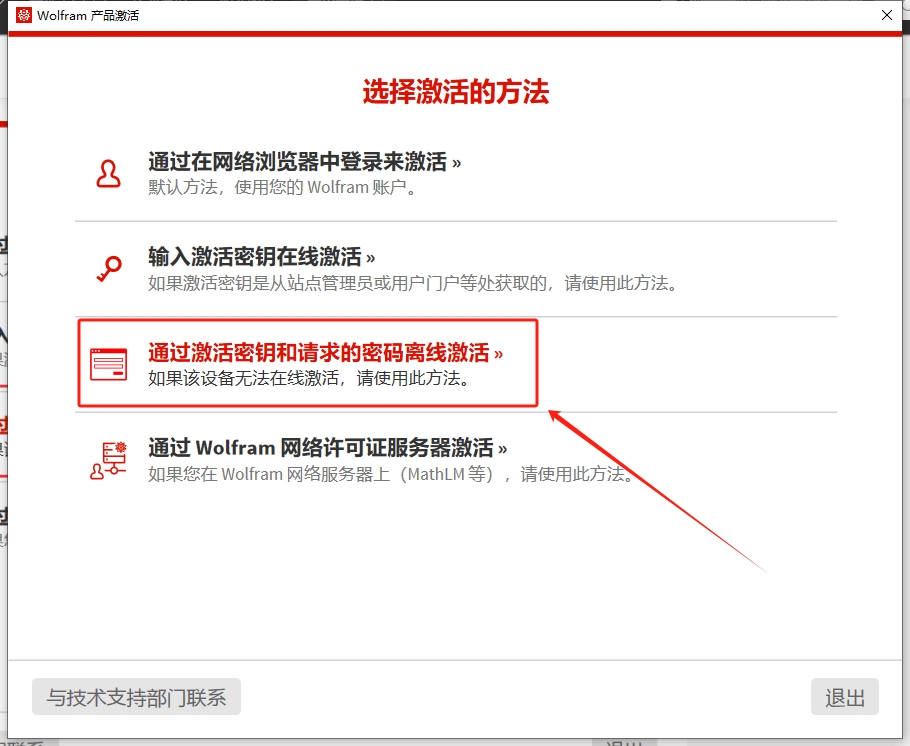
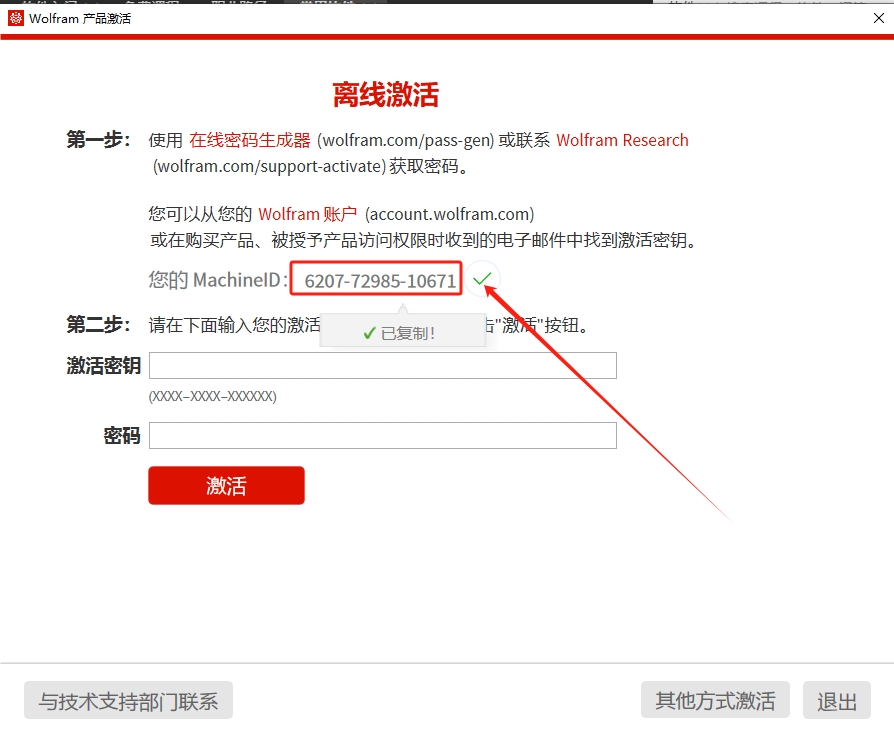
Perl provider (optional) ~ - WARNING "Neovim::Ext" cpan module is not installed - ADVICE: - See :help |provider-perl| for more information. - You may disable this provider (and warning) by adding `let g:loaded_perl_provider = 0` to your init.vim - WARNING No usable perl executable found
Perl provider (optional) ~ - perl executable: /usr/bin/perl - OK Latest "Neovim::Ext" cpan module is installed: class is experimental at (eval 8) line 2. field is experimental at (eval 8) line 4. method is experimental at (eval 8) line 5. field is experimental at (eval 8) line 6. method is experimental at (eval 8) line 7. field is experimental at (eval 8) line 8. method is experimental at (eval 8) line 9. field is experimental at (eval 8) line 10. method is experimental at (eval 8) line 11. field is experimental at (eval 8) line 12. method is experimental at (eval 8) line 13. field is experimental at (eval 8) line 14. method is experimental at (eval 8) line 15. class is experimental at (eval 9) line 2. field is experimental at (eval 9) line 4. method is experimental at (eval 9) line 5. field is experimental at (eval 9) line 6. method is experimental at (eval 9) line 7. 0.06
-- No need to copy this inside `setup()`. Will be used automatically. { -- Module mappings. Use `''` (empty string) to disable one. mappings = { start = 'ga', start_with_preview = 'gA', },
-- Modifiers adding pre-steps ['f'] = --<function: filter parts by entering Lua expression>, ['i'] = --<function: ignore some split matches>, ['p'] = --<function: pair parts>, ['t'] = --<function: trim parts>,
-- Delete some last pre-step ['<BS>'] = --<function: delete some last pre-step>,
-- Special configurations for common splits ['='] = --<function: enhanced setup for '='>, [','] = --<function: enhanced setup for ','>, [' '] = --<function: enhanced setup for ' '>, },
let fcitx5state=system("fcitx5-remote") autocmd InsertLeave * :silentlet fcitx5state=system("fcitx5-remote")[0] | silent !fcitx5-remote -c" Disable the input method when exiting insert mode and save the state autocmd InsertEnter * :silentif fcitx5state == 2 | callsystem("fcitx5-remote -o") | endif
[Desktop Entry] Version=1.0 Type=Application Name=E-book viewer GenericName=Viewer for E-books Comment=Viewer for E-books in all the major formats TryExec=/opt/calibre/ebook-viewer Exec=/opt/calibre/ebook-viewer --detach %f Icon=calibre-viewer Categories=Office;Viewer; Keywords=epub;ebook;viewer; MimeType=application/x-cbz;application/x-cbc;application/x-mobipocket-ebook;application/vnd.openxmlformats-officedocument.wordprocessingml.document;application/ereader;application/x-cb7;application/x-mobi8-ebook;application/vnd.ms-word.document.macroenabled.12;application/vnd.ctc-posml;application/epub+zip;application/oebps-package+xml;image/vnd.djvu;application/x-cbr;application/x-sony-bbeb;application/x-mobipocket-subscription;
Linux KDE和Linux GNOME桌面系统都使用 Desktop
Entry
Specification来描述程序启动配置信息。Desktop Entry 文件标准是由
X Desktop Group 制定的,目前最新的版本是"Desktop Entry
Specification 1.5"。